深度強化學習(Deep Reinforcement Learning, DRL)中的兩大主要方法:Model-free Approach和 Model-based Approach。
這種方法適用於無法窮舉所有可能狀態和行動的環境。根據學習策略的不同,分為兩大類:Policy-based(基於策略的方法)和 Value-based(基於價值的方法)。
核心概念:訓練一個Critic,負責對目前的狀況給予評價。
Value-Based方法的核心在於學習狀態(state)或狀態-行動(state-action)對的價值,以此來決定最佳行動。
核心概念:訓練一個Actor,負責執行動作。
Policy-Based方法直接學習一個策略(policy),而不是價值函數。這個策略決定在每個狀態下應該採取的行動。
也可以將兩種方法結合形成 Actor-Critic 方法
Q-Learning 是一種強化學習(Reinforcement Learning)演算法,用於解決在一個代理(agent)與環境(environment)互動過程中,如何學習到最佳行為策略(policy)的方法,主要目的是找到一個策略,使得在長期內獲得的回報(reward)最大化。
他的公式表示如下: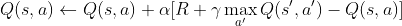
可能有人看到數學就會覺得好難,不想往下讀了,等等!!先別走,其實他沒有你想像中的那麼難,我將裡面一個符號一個符號拆開來解釋。
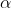 是
是學習率(learning rate),決定新信息與現有信息的融合程度。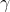 是
是折扣因子(discount factor),用來考慮未來獎勵的重要性。他實際上會使用一個叫做Q-table的表格,來儲存每個情況下最佳的 Q-value,並根據獎勵來更新 Q-table,並逐漸學會最佳策略。
我們用一個簡單的遊戲來說明 Q-Learning。假設我們有一個迷宮遊戲,代理人(Agent)從起點開始,需要找到終點,並在過程中收集獎勵。迷宮中有多個位置,每個位置可以選擇向上、向下、向左或向右移動。
在迷宮遊戲中,代理人每次移動都會進入一個新狀態,並且根據這個新狀態獲得相應的獎勵。代理人需要根據自己的經驗來做出最佳決策,以最大化累積的獎勵。
假設代理人目前在位置 (0,0),這是起點。代理人有兩個選擇:
由於代理人還沒有任何經驗,所以可以隨機選擇一個行動。假設代理人選擇向右移動到 (0,1),並在新位置 (0,1) 獲得一個小獎勵(例如 +1 分)。
現在代理人位於狀態 s1,並有兩個選擇:a1 向下移動和 a2 向右移動。假設在狀態 s1 下,選擇 a2 的獎勵比 a1 大,所以我們更新 Q 表來反映這一點。
| a1 | a2 | |
|---|---|---|
| s1 | 0 | 0 |
| s2 | 0 | 0 |
代理人執行行動並獲得獎勵
假設代理人從狀態 s1 開始,選擇行動 a2(向右移動),並到達新狀態 s2,在 s2 獲得獎勵 R。我們假設獎勵為 +1。
計算Q值更新
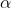 = 0.1
= 0.1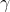 = 0.9
= 0.9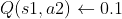
| a1 | a2 | |
|---|---|---|
| s1 | 0 | 0.1 |
| s2 | 0 | 0.1 |
這個過程在代理人與環境互動時會反覆進行,每次都會更新 Q 表,以使其更準確地預測每個行動的長期價值。這樣,代理人可以逐步學習如何在不同的狀態下選擇最優行動。
實際運行中,s2 可能會有其他後續的狀態,這取決於代理人的探索過程。你應該根據代理人的探索更新 Q 表,並不僅僅依賴一次獎勵來更新。
今天就到這裡,明天會繼續延伸下去,希望大家可以繼續收看下去。
(為什麼這裡寫數學式這麼麻煩 ,原本以為寫在hackmd可以直接無痛移植過來貼上,結果好像不行。)
,原本以為寫在hackmd可以直接無痛移植過來貼上,結果好像不行。)

